Climathon (07.2023)
At the moment, almost everything is missing to make the mobility transition a success and to reduce emissions from the sector: Political will, investments in railroads, safe bike lanes... What is available in ever greater quantities, but which we have so far used far too rarely for mobility campaigns, is data around the topic of transport: mobility data, air quality data, registration data, roadway data - the list could go on and on. We often lack the skills to analyze the data or turn it into catchy tools. Together with Greenpeace, we are organizing a Climateathon in July to change this.
The event will focus on the question: "How can programming with the computer language Python contribute to increasing sustainability?" The goal is to learn the basics and advanced features of programming with Python, a well-known, easily accessible programming language. To this end, we will work in Python during a hackathon weekend at the Greenpeace camp (July 7-9) with various examples from the field of mobility research, accompanied by some exciting keynotes. In the following week, participants will work on their own projects under the daily guidance of a tutor and digital assistance.
When & Where?
Part 1: Hackathon at the action camp (07.07., 16:00 to 09.07., 15:00; overnight stay on site)
Part 2: Independent project development (10. to 13.07.)
Part 3: Virtual final conference (14.07., 17:00 to 20:00)
Who?
Anyone with an interest in the mobility transition and a desire to program. No previous knowledge necessary. Max. 24 participants.
The seminar language is German and English.
Programme
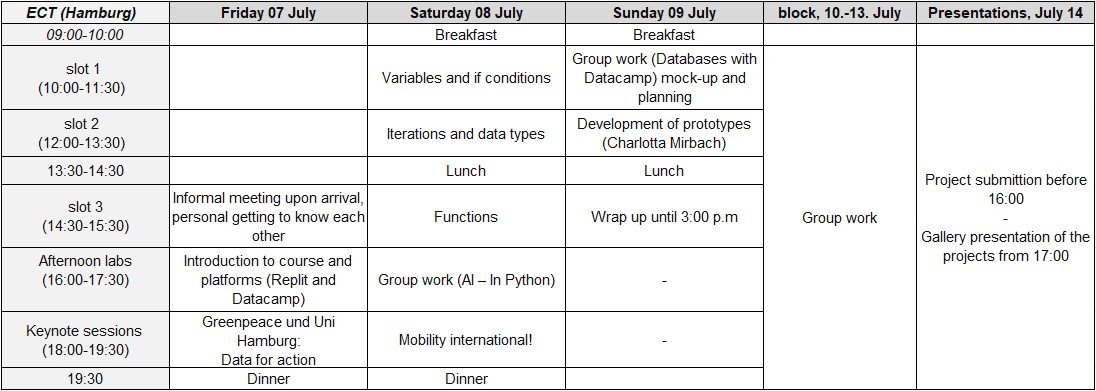
Our course is guided by the following plan, which we have developed over several years of teaching Python for Data Science using an object-oriented modeling and programming approach. The method is inductive, meaning that we start the first units with as little theory as possible so that students can try out the exercises (some of which have already been developed and are still being improved) and figure out for themselves how it works. After this first phase, we deepen the theory in a more deductive way. We start with the concept of variables, continue with first control structures (if-application/iteration), continue working with different types of data in the main example and finish with the topic of functions. The goal of the course is for students to complete a self-created analysis, which we call a prototype. We also devote a similar approach to Open Science. Drawing on their own experiences, participants discuss the role of Open Science for action. They then design a roadmap for publishing their own content according to FAIR Scientific Data Stewardship principles in open online platforms (e.g., GitHub). This process builds the capacity to develop, analyze, and critically manage digital data.