Klimathon (07.2023)
Aktuell fehlt es noch an fast allem, um die Verkehrswende zum Erfolg und die Emissionen aus dem Sektor runterzubringen: Politischer Wille, Investitionen in die Bahn, sichere Radwege… Was es in immer größerem Umfang gibt, wir aber bisher viel zu selten für Mobilitätskampagnen nutzen sind Daten rund um das Thema Verkehr: Mobilitätsdaten, Luftqualitätsdaten, Zulassungsdaten, Streckendaten - die Liste ließe sich lange fortsetzen. Oft fehlt es uns an den Fähigkeiten, die Daten zu analysieren oder in eingängige Tools zu verwandeln. Gemeinsam mit Greenpeace veranstalten wir im Juli einen Klimathon, um dies zu ändern.
Im Mittelpunkt der Veranstaltung steht die Frage: "Wie kann die Programmierung mit der Computersprache Python zur Steigerung der Nachhaltigkeit beitragen?" Ziel ist es, die Grundlagen und weiterführenden Möglichkeiten der Programmierung mit Python, einer bekannten, leicht zugänglichen Programmiersprache, zu erlernen. Zu diesem Zweck werden wir an einem Hackathon Wochenende im Greenpeace-Lager (7.-9. Juli) mit verschiedenen Beispielen aus dem Bereich Mobilitätsforschung in Python arbeiten und begleitend einige spannende Keynotes hören. In der darauffolgenden Woche werden die TeilnehmerInnen unter täglicher Anleitung eines Tutors oder einer Tutorin und digitaler Hilfestellung an ihren eigenen Projekten arbeiten.
Wann & Wo?
Teil 1: Hackathon im Aktionslager (07.07., 16:00 bis 09.07., 15:00; Übernachtung vor Ort)
Teil 2: Selbstständige Weiterentwicklung der Projekte (10. bis 13.07.)
Teil 3: Virtuelle Abschlusskonferenz (14.07., 17:00 bis 20:00)
Wer?
Jede und jeder mit Interesse an der Verkehrswende und Lust auf Programmieren. Keine Vorkenntnisse nötig. Max. 24 Teilnehmende.
Die Seminar-Sprache ist Deutsch und Englisch.
Programm
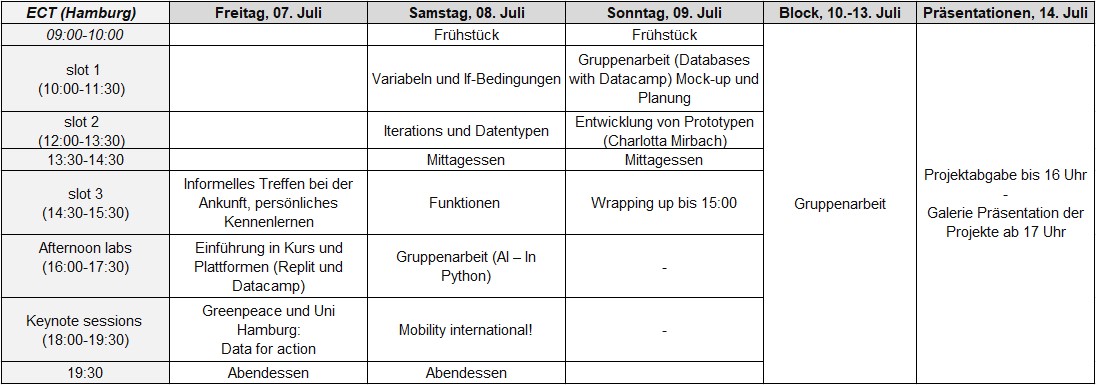
Unsere Veranstaltung orientiert sich an dem folgenden Plan, den wir im Laufe mehrerer Jahre entwickelt haben, in denen wir Python für Data Science unter Verwendung eines objektorientierten Modellierungs- und Programmieransatzes unterrichtet haben. Die Methode ist induktiv, d.h. wir beginnen die ersten Einheiten mit so wenig Theorie wie möglich, damit die Lernenden die Übungen (die teilweise bereits entwickelt wurden und immer noch verbessert werden) ausprobieren und selbst herausfinden, wie es funktioniert. Nach dieser ersten Phase vertiefen wir die Theorie auf eine eher deduktive Weise. Wir beginnen mit dem Variablenkonzept, fahren mit den ersten Kontrollstrukturen fort (if-Anwendung/Iteration), arbeiten im Hauptbeispiel mit verschiedenen Arten von Datentypen weiter und schließen mit dem Thema der Funktion ab. Das Ziel des Kurses ist es, dass die Lernenden eine selbst erstellte Analyse, die wir als Prototyp bezeichnen, fertigstellen. Einen ähnlichen Ansatz widmen wir auch Open Science. Ausgehend von ihren eigenen Erfahrungen diskutieren die Teilnehmer/innen über die Rolle von Open Science für Aktion. Anschließend entwerfen sie einen Fahrplan für die Veröffentlichung ihrer eigenen Inhalte gemäß den FAIR Scientific Data Stewardship Prinzipien in offenen Online-Plattformen (z.B. GitHub). Dieser Prozess baut die Fähigkeit auf, digitale Daten zu entwickeln, zu analysieren und kritisch zu verwalten.